 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal2Sim in HOI: Toward Physically Plausible HOI Reconstruction from Monocular Videos
May 14, 2026Recovering 4D human-object interaction (HOI) from monocular video is a key step toward scalable 3D content creation, embodied AI, and simulation-based learning. Recent methods can reconstruct temporally coherent human and object trajectories, but these trajectories often remain visual artifacts while failing to preserve stable contact, functional manipulation, or physical plausibility when used as reference motions for humanoid-object simulation. This reveals a fundamental interaction gap: HOI reconstruction should not stop at tracking a human and an object, but should recover the relation that makes their motion a coherent interaction. We introduce $\textbf{HA-HOI}$, a framework for reconstructing physically plausible 4D HOI animation from in-the-wild monocular videos. Instead of treating the human and object as independent entities in an ambiguous monocular 3D space, we propose a $\textit{human-first, object-follow}$ formulation. The human motion is recovered as the interaction anchor, and the object is reconstructed, aligned, and refined relative to the human action. The resulting kinematic trajectory is then projected into a physics-based humanoid-object simulation, where it acts as a teacher trajectory for stable physical rollout. Across benchmark and in-the-wild videos, $\textbf{HA-HOI}$ improves human-object alignment, contact consistency, temporal stability, and simulation readiness over prior monocular HOI reconstruction methods. By moving beyond visually plausible trajectory recovery toward physically grounded interaction animation, our work takes a step toward turning general monocular HOI videos into scalable demonstrations for humanoid-object behavior. Project page: https://knoxzhao.github.io/real2sim_in_HOI/
TransmissiveGS: Residual-Guided Disentangled Gaussian Splatting for Transmissive Scene Reconstruction and Rendering
May 11, 2026Transmissive scenes are ubiquitous in daily life, yet reconstructing and rendering them remains highly challenging due to the inherent entanglement between near-field reflections from the surrounding environment on the transmissive surface, and the transmitted content of the scene behind it. This coupling gives rise to dual surface geometries and dual radiance components within each observation, posing ambiguities for standard methods. We present TransmissiveGS, a novel framework for disentangled reconstruction and rendering of transmissive scenes. Specifically, we model the scene with a dual-Gaussian representation and introduce a deferred shading function to jointly render the two Gaussian components. To separate reflection and transmission, we exploit the inherent multi-view inconsistency of reflections and leverage the residuals from reconstructing multi-view consistent content as cues for disentangled geometry and appearance modeling. We further propose a reflection light field that enables high-fidelity estimation of near-field reflections. During training, we introduce a high-frequency regularization to preserve fine details. We also contribute a new synthetic dataset for evaluating transmissive surface reconstruction. Experiments on both synthetic and real-world scenes demonstrate that TransmissiveGS consistently outperforms prior Gaussian Splatting-based methods in both reconstruction and rendering quality for transmissive scenes.
SK-Adapter: Skeleton-Based Structural Control for Native 3D Generation
Mar 14, 2026Native 3D generative models have achieved remarkable fidelity and speed, yet they suffer from a critical limitation: inability to prescribe precise structural articulations, where precise structural control within the native 3D space remains underexplored. This paper proposes SK-Adapter, a simple and yet highly efficient and effective framework that unlocks precise skeletal manipulation for native 3D generation. Moving beyond text or image prompts, which can be ambiguous for precise structure, we treat the 3D skeleton as a first-class control signal. SK-Adapter is a lightweight structural adapter network that encodes joint coordinates and topology into learnable tokens, which are injected into the frozen 3D generation backbone via cross-attention. This smart design allows the model to not only effectively "attend" to specific 3D structural constraints but also preserve its original generative priors. To bridge the data gap, we contribute Objaverse-TMS dataset, a large-scale dataset of 24k text-mesh-skeleton pairs. Extensive experiments confirm that our method achieves robust structural control while preserving the geometry and texture quality of the foundation model, significantly outperforming existing baselines. Furthermore, we extend this capability to local 3D editing, enabling the region specific editing of existing assets with skeletal guidance, which is unattainable by previous methods. Project Page: https://sk-adapter.github.io/
CoT-Seg: Rethinking Segmentation with Chain-of-Thought Reasoning and Self-Correction
Jan 24, 2026Existing works of reasoning segmentation often fall short in complex cases, particularly when addressing complicated queries and out-of-domain images. Inspired by the chain-of-thought reasoning, where harder problems require longer thinking steps/time, this paper aims to explore a system that can think step-by-step, look up information if needed, generate results, self-evaluate its own results, and refine the results, in the same way humans approach harder questions. We introduce CoT-Seg, a training-free framework that rethinks reasoning segmentation by combining chain-of-thought reasoning with self-correction. Instead of fine-tuning, CoT-Seg leverages the inherent reasoning ability of pre-trained MLLMs (GPT-4o) to decompose queries into meta-instructions, extract fine-grained semantics from images, and identify target objects even under implicit or complex prompts. Moreover, CoT-Seg incorporates a self-correction stage: the model evaluates its own segmentation against the original query and reasoning trace, identifies mismatches, and iteratively refines the mask. This tight integration of reasoning and correction significantly improves reliability and robustness, especially in ambiguous or error-prone cases. Furthermore, our CoT-Seg framework allows easy incorporation of retrieval-augmented reasoning, enabling the system to access external knowledge when the input lacks sufficient information. To showcase CoT-Seg's ability to handle very challenging cases ,we introduce a new dataset ReasonSeg-Hard. Our results highlight that combining chain-of-thought reasoning, self-correction, offers a powerful paradigm for vision-language integration driven segmentation.
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Jun 05, 2025



SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
Agentic 3D Scene Generation with Spatially Contextualized VLMs
May 26, 2025Despite recent advances in multimodal content generation enabled by vision-language models (VLMs), their ability to reason about and generate structured 3D scenes remains largely underexplored. This limitation constrains their utility in spatially grounded tasks such as embodied AI, immersive simulations, and interactive 3D applications. We introduce a new paradigm that enables VLMs to generate, understand, and edit complex 3D environments by injecting a continually evolving spatial context. Constructed from multimodal input, this context consists of three components: a scene portrait that provides a high-level semantic blueprint, a semantically labeled point cloud capturing object-level geometry, and a scene hypergraph that encodes rich spatial relationships, including unary, binary, and higher-order constraints. Together, these components provide the VLM with a structured, geometry-aware working memory that integrates its inherent multimodal reasoning capabilities with structured 3D understanding for effective spatial reasoning. Building on this foundation, we develop an agentic 3D scene generation pipeline in which the VLM iteratively reads from and updates the spatial context. The pipeline features high-quality asset generation with geometric restoration, environment setup with automatic verification, and ergonomic adjustment guided by the scene hypergraph. Experiments show that our framework can handle diverse and challenging inputs, achieving a level of generalization not observed in prior work. Further results demonstrate that injecting spatial context enables VLMs to perform downstream tasks such as interactive scene editing and path planning, suggesting strong potential for spatially intelligent systems in computer graphics, 3D vision, and embodied applications.
ThinkVideo: High-Quality Reasoning Video Segmentation with Chain of Thoughts
May 24, 2025



Reasoning Video Object Segmentation is a challenging task, which generates a mask sequence from an input video and an implicit, complex text query. Existing works probe into the problem by finetuning Multimodal Large Language Models (MLLM) for segmentation-based output, while still falling short in difficult cases on videos given temporally-sensitive queries, primarily due to the failure to integrate temporal and spatial information. In this paper, we propose ThinkVideo, a novel framework which leverages the zero-shot Chain-of-Thought (CoT) capability of MLLM to address these challenges. Specifically, ThinkVideo utilizes the CoT prompts to extract object selectivities associated with particular keyframes, then bridging the reasoning image segmentation model and SAM2 video processor to output mask sequences. The ThinkVideo framework is training-free and compatible with closed-source MLLMs, which can be applied to Reasoning Video Instance Segmentation. We further extend the framework for online video streams, where the CoT is used to update the object of interest when a better target starts to emerge and becomes visible. We conduct extensive experiments on video object segmentation with explicit and implicit queries. The results show that ThinkVideo significantly outperforms previous works in both cases, qualitatively and quantitatively.
Multimodal Generation of Animatable 3D Human Models with AvatarForge
Mar 11, 2025We introduce AvatarForge, a framework for generating animatable 3D human avatars from text or image inputs using AI-driven procedural generation. While diffusion-based methods have made strides in general 3D object generation, they struggle with high-quality, customizable human avatars due to the complexity and diversity of human body shapes, poses, exacerbated by the scarcity of high-quality data. Additionally, animating these avatars remains a significant challenge for existing methods. AvatarForge overcomes these limitations by combining LLM-based commonsense reasoning with off-the-shelf 3D human generators, enabling fine-grained control over body and facial details. Unlike diffusion models which often rely on pre-trained datasets lacking precise control over individual human features, AvatarForge offers a more flexible approach, bringing humans into the iterative design and modeling loop, with its auto-verification system allowing for continuous refinement of the generated avatars, and thus promoting high accuracy and customization. Our evaluations show that AvatarForge outperforms state-of-the-art methods in both text- and image-to-avatar generation, making it a versatile tool for artistic creation and animation.
Dynamic Path Navigation for Motion Agents with LLM Reasoning
Mar 10, 2025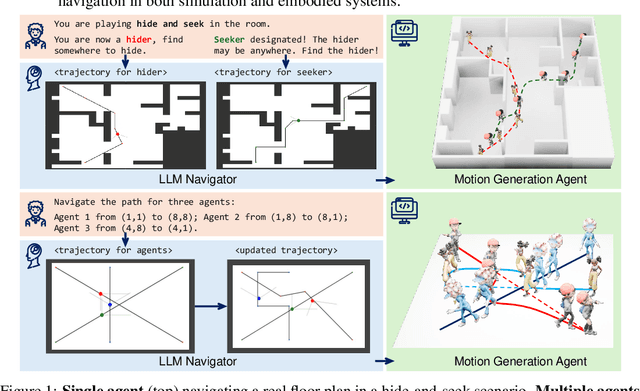
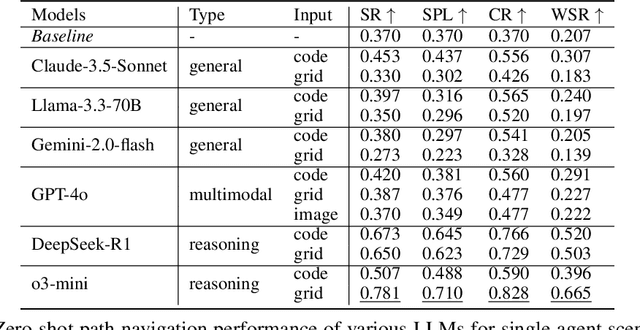
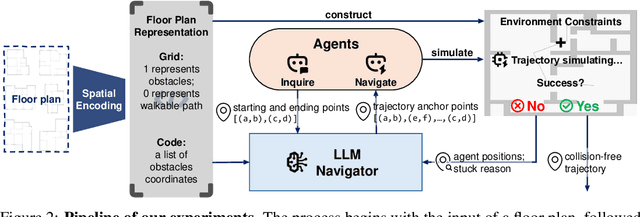
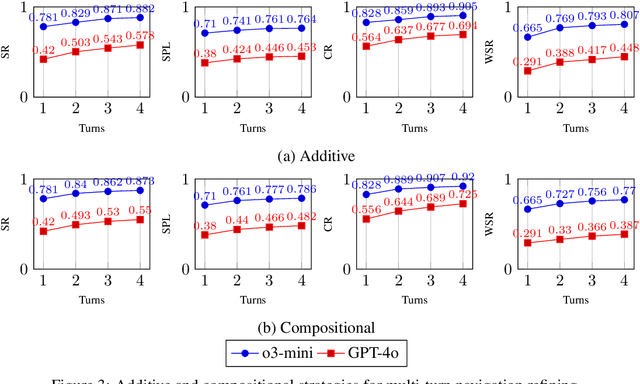
Large Language Models (LLMs) have demonstrated strong generalizable reasoning and planning capabilities. However, their efficacies in spatial path planning and obstacle-free trajectory generation remain underexplored. Leveraging LLMs for navigation holds significant potential, given LLMs' ability to handle unseen scenarios, support user-agent interactions, and provide global control across complex systems, making them well-suited for agentic planning and humanoid motion generation. As one of the first studies in this domain, we explore the zero-shot navigation and path generation capabilities of LLMs by constructing a dataset and proposing an evaluation protocol. Specifically, we represent paths using anchor points connected by straight lines, enabling movement in various directions. This approach offers greater flexibility and practicality compared to previous methods while remaining simple and intuitive for LLMs. We demonstrate that, when tasks are well-structured in this manner, modern LLMs exhibit substantial planning proficiency in avoiding obstacles while autonomously refining navigation with the generated motion to reach the target. Further, this spatial reasoning ability of a single LLM motion agent interacting in a static environment can be seamlessly generalized in multi-motion agents coordination in dynamic environments. Unlike traditional approaches that rely on single-step planning or local policies, our training-free LLM-based method enables global, dynamic, closed-loop planning, and autonomously resolving collision issues.
Think Before You Segment: High-Quality Reasoning Segmentation with GPT Chain of Thoughts
Mar 10, 2025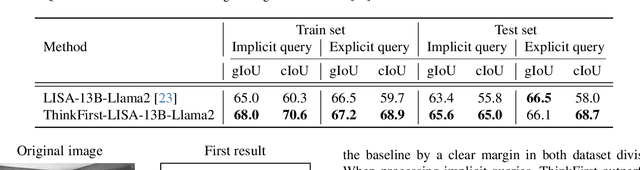

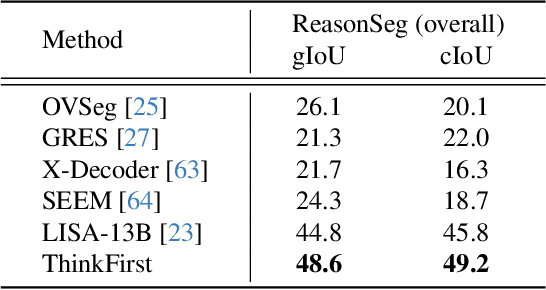

Reasoning segmentation is a challenging vision-language task that aims to output the segmentation mask with respect to a complex, implicit, and even non-visual query text. Previous works incorporated multimodal Large Language Models (MLLMs) with segmentation models to approach the difficult problem. However, their segmentation quality often falls short in complex cases, particularly when dealing with out-of-domain objects with intricate structures, blurry boundaries, occlusions, or high similarity with surroundings. In this paper, we introduce ThinkFirst, a training-free reasoning segmentation framework that leverages GPT's chain of thought to address these challenging cases. Our approach allows GPT-4o or other powerful MLLMs to generate a detailed, chain-of-thought description of an image. This summarized description is then passed to a language-instructed segmentation assistant to aid the segmentation process. Our framework allows users to easily interact with the segmentation agent using multimodal inputs, such as easy text and image scribbles, for successive refinement or communication. We evaluate the performance of ThinkFirst on diverse objects. Extensive experiments show that, this zero-shot-CoT approach significantly improves the vanilla reasoning segmentation agent, both qualitatively and quantitatively, while being less sensitive or critical to user-supplied prompts after Thinking First.